Here come the rake stepper
So I have really been trying to make the LLM generated code thing work for me.
If it's not entirely clear from my previous writing, I am a skeptic when it comes to LLMs in general. I also happen to have something of a pathological aversion to skepticism that makes me really dig in to something when I'm skeptical to see if there is anything valuable in the thing.
To that end, I have had some moderately interesting results from LLMs as a plain text generator. Perhaps my most successful usage was the time I read Patrick Lencioni's book about meetings and really, really did not like it. I explained to an LLM (probably Claude) what I didn't like about the book and that I wanted to read something about meetings that had more rigour and some attempt at providing data or research to back up claims. Claude recommended The Surprising Science of Meetings, by Steven Rogelberg, which was a much better book!
Thanks, Claude!
So back to LLMs as 'Junior Developers' or 'Principal Engineers' (depending on who you are listening to).
Some of the push back against skeptics I've heard previously amounts to "you're prompting it wrong!"
How do you prompt it wrong?
- Using the 'wrong' model
- Using an insufficient prompt
- Not providing appropriate context
- Ignoring token limits
That kind of thing.
I have been guilty of poor LLM usage in trying to write code. I've slapped poorly constructed prompts together and picked a random model. I've let it run somewhat wild and then been disappointed with the results.
But I've tried it the other way too.
I read Harper's blog post about his workflow: My LLM codegen workflow atm.
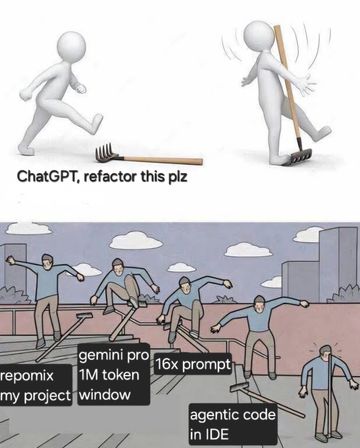
I've used Repomix to turn large code bases into something an LLM can grapple with in one go.
I've used Google's AI Studio, with Gemini Pro and it's 1 million token window reasoning model to construct work plans and detailed breakdowns other LLM agents in my IDE can enact.
I've crafted detailed system prompts and equally detailed task prompts.
I've learned which models are suited to which tasks. Turns out "bigger number; newer model" is not the correct heuristic for this! Claude Sonnet 3.5 is quite good. Claude Sonnet 3.7 is like a shark in a feeding frenzy, leaving your codebase a swirling mess of blood and chum in the water.
They should put that in the adverts actually. Anthropic, I'm available for your copywriting needs.
And you know what?
It's still nearly ok at taking on a moderate task in an existing production codebase.
All that effort and fussing around with tools, and I'm still only 85% of the way there, and the remaining 15% is only really achievable if you undo all the LLM work and just start again yourself from scratch.
A recent blog post that has really resonated with me is this one: "Generative AI runs on gambling addiction — just one more prompt, bro!"
Anyway, all this has left me not really much closer to the promised AI nirvana, but it did inspire me to make a meme.
- Previous: Introspectives: Having 1:1s with yourself
- Next: Intention